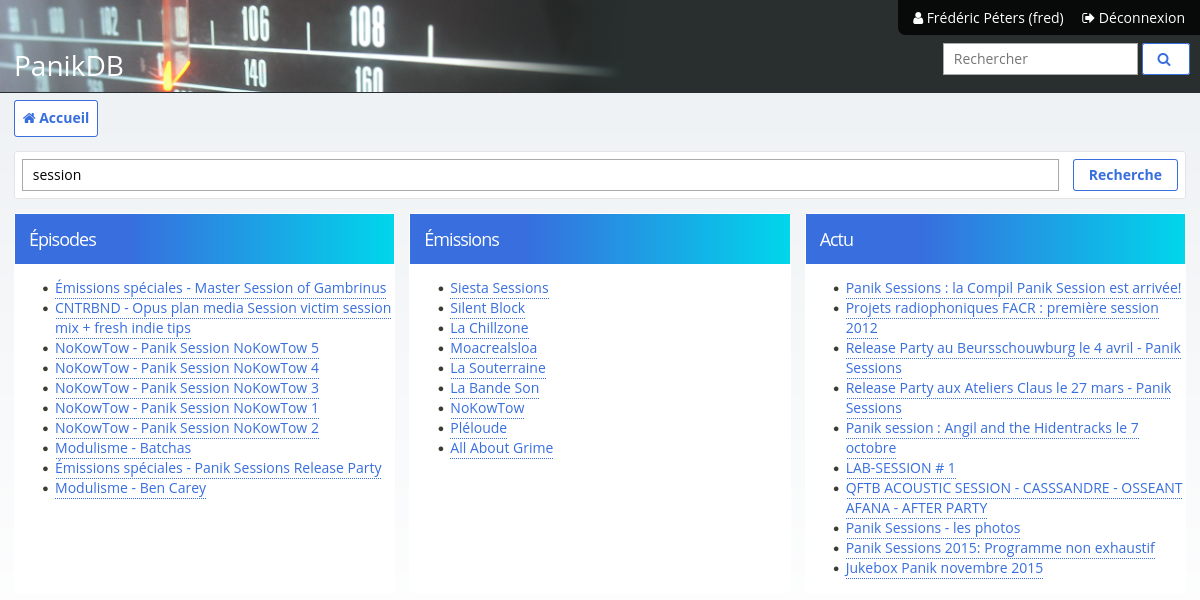
Recherche plein texte, passage de solr à PostgreSQL
Un peu à la mode quand on était il y a des années à réfléchir au site web de radio Panik il y avait la recherche par facettes, c’est-à-dire la possibilité d’affiner·réduire les résultats en posant des critères supplémentaires, les émissions → les émissions musicales → les émissions musicales de moins d’une heure → les émissions musicales de moins d’une heure avec mot-clé new york, etc. C’était quelque chose mis en avant par des moteurs de recherche tels que Solr, le module django-haystack était là pour assurer une bonne intégration et c’était disponible dans Debian.
Comme ça assurait très bien la recherche plein texte également, qu’il y avait quelques autres fonctionnalités utiles et que j’avais déjà un peu travaillé avec, j’étais parti là-dessus et ça tournait en se laissant oublier, c’était très bien. Bien sûr parfois les mises à jour étaient un peu galères (cf cette note par exemple) mais ça n’est pas tous les jours.
Pas tous les jours mais récemment il y a eu la mise à jour vers Debian 11 (bullseye) et il n’y a pas eu de problème mais c’était pour la pire raison qui soit : le paquet a tout bonnement été retiré,
lucene-solr (3.6.2+dfsg-23) unstable; urgency=medium * Declare compliance with Debian Policy 4.5.1. * Switch to debhelper-compat = 13. * Drop solr-tomcat, solr-jetty, solr-common and libsolr-java. The version of solr in Debian is outdated and newer versions are not viable to maintain. An alternative version packaged with jdeb or similar tools may be available via the contrib repository in the future. (Closes: #982001, #581435, #800983, #840827, #842402, #842706, #931845, #956464) -- Markus Koschany <apo@debian.org> Mon, 22 Feb 2021 17:02:39 +0100
Ça tournait à Panik parce que c’était déjà installé mais pour les nouvelles installations (radio sud, radio air libre, voire une réinstallation à Panik), ça n’allait pas marcher comme ça. Alors, même si la recherche n’est qu’assez peu utilisée (les gens voient leurs émissions, leurs épisodes récents, ont rarement besoin de chercher les archives), je viens de reprendre ça pour simplement offrir une recherche plein texte, en utilisant seulement PostgreSQL.
C’est très facile, tout le nécessaire est déjà disponible et documenté dans Django (recherche plein texte); bref ça donne une vue qui recherche indépendamment dans les émissions, les épisodes, et les actus,
class Search(TemplateView):
template_name = 'search/search.html'
def get_context_data(self, **kwargs):
context = super().get_context_data(**kwargs)
context['query'] = self.request.GET.get('q', '')
vector = (
SearchVector('title', weight='A')
+ SearchVector('subtitle', weight='A')
+ SearchVector('text', weight='B')
)
query = SearchQuery(self.request.GET.get('q', ''))
context['hits'] = {
'episodes': Episode.objects.annotate(
rank=SearchRank(vector, query)
)
.filter(rank__gte=0.1)
.select_related('emission')
.order_by('-rank')[:10],
'emissions': Emission.objects.annotate(
rank=SearchRank(vector, query)
)
.filter(rank__gte=0.1)
.order_by('-rank')[:10],
'newsitems': NewsItem.objects.annotate(
rank=SearchRank(vector, query)
)
.filter(rank__gte=0.1)
.order_by('-rank')[:10],
}
return context
Sur le volume de données qu’on a, et le peu d’usage de la recherche, ça tourne très bien ainsi. Si à un moment il fallait aller plus loin il y a la documentation PostgreSQL (Full Text Search / tables and indexes) pour la création d’index mais aussi la possibilité de concaténer nativement les données.
En attendant ça marche déjà très bien comme ça et surtout c’était vraiment très rapide à mettre en place.